
Electronics#ar #VR #AR Glasses #Augmented Reality #Virtual Reality #techtok #cftech
Use this section to provide a description of your blog./pages/blog
How does the true spatial interaction and depth-critical workflows in the AR glasses?
Posted by Technology Co., Ltd Shenzhen Mshilor
“True spatial interaction” in AR glasses means the system can understand real 3D space, track the user’s viewpoint precisely, and then render/allow interaction in a way that feels physically correct—especially when the user needs accurate depth (near vs far), scale, and alignment. For depth-critical workflows, this must work reliably in motion.

1) What makes interaction “spatial”?
A. 6-DoF tracking (pose)
The glasses continuously estimate the user’s head pose:
- Position in 3D space (x, y, z)
- Orientation (roll/pitch/yaw)
Depth-critical workflows depend on low drift and low latency so that virtual objects stay “stuck” to the real world.
B. World understanding (mapping)
The system builds a representation of the environment:
- Feature points / SLAM map
- Planes (walls/floors) and sometimes meshes
- Recognized objects or anchors (e.g., “this specific machine part”)
This provides a coordinate frame so a virtual object can be placed at a specific real location.
C. Anchoring & stability
When you “place” something (a label, tool guide, 3D model), it must remain fixed relative to the real scene even when you move. Depth-critical tasks fail when anchors slide or scale incorrectly.
2) What makes it “depth-critical”?
Depth-critical means errors in depth translate directly into wrong actions, for example:
- Aligning fasteners or parts
- Drilling/cutting path guidance
- Training where correct positioning matters
- Medical/procedural-like guidance (even if not a medical device)
So the system must deliver:
- Accurate relative depth (near vs far)
- Correct scale (1:1 size or known calibration)
- Consistent parallax (stereo cues + correct rendering)
3) How stereo/binocular helps depth-critical workflows
Binocular glasses can render stereoscopic depth:
- Each eye sees a slightly different image, matching real-world parallax
- This improves perceived depth and makes “reach/align” tasks more natural
However, stereo only helps if:
- Optical alignment is correct
- Tracking is good
- Rendering matches the user’s actual viewpoint (latency matters)
4) Interaction methods that use 3D space
To interact “in space,” the system needs a way to target 3D points/objects:
A. Gaze + ray casting (common)
- Eye tracking gives a gaze direction
- The system casts a ray into the reconstructed scene
- It determines the 3D point you’re looking at (for selection, grabbing, “tap in space”)
B. Controller/hand tracking
- Hand/controller pose is tracked in 3D
- The user “grabs” virtual objects or aligns tools
- Constraints help prevent unrealistic interactions (e.g., snapping to edges/axes)
C. Spatial gestures
- Pinch to select
- Grab to move
- Rotate to align
- Confirm/cancel actions with air taps or hand poses
Depth-critical benefit: the “target” is a 3D coordinate, not a 2D screen pixel.
5) The rendering pipeline must be correct
For depth-critical workflows, rendering must be physically consistent:
- Compute gaze/head pose at render time
- Project 3D anchors into the display
- Apply occlusion handling (virtual object hidden behind real objects when appropriate)
- Maintain correct depth ordering (so a virtual tool guide doesn’t “float through” the real tool)
This often requires:
- Depth map estimation (from cameras)
- Occlusion meshes or learned depth
- Accurate camera calibration
6) Latency and prediction (why timing is critical)
If pose updates arrive late:
- The virtual object appears to lag behind
- Stereo depth cues can become uncomfortable
- Alignment tasks become error-prone
So systems use:
- Sensor fusion (IMU + vision)
- Motion prediction (estimate where the user will be at display time)
- Late latching/reprojection (update pose as late as possible before scanout)
7) Typical depth-critical workflow examples (how it plays out)
A. Maintenance/assembly “Place the part here”
- The system detects the assembly area/anchors (or recognizes the part)
- Shows a 3D placement ghost/guide at the correct location
- User aligns screws/parts using gaze + hand/controller targeting
- Occlusion + stereo help confirm “in/out” depth
B. “Follow the drill path.”
- A path is computed in 3D, tied to the real surface
- As you move, the path remains locked to the surface
- Depth accuracy ensures the virtual trajectory corresponds to the physical cut/drill location
C. Training simulation for correct positioning
- Virtual anatomy/tools placed in real-ish space
- Scoring based on 3D deviation tolerances
- Binoculars improve realism, but tracking accuracy is the bigger determinant
8) What could still go wrong (key failure modes)
- SLAM drift → anchors slowly shift, causing depth errors
- Scale miscalibration → virtual objects seem too big/small
- Bad occlusion → depth looks wrong (virtual tool appears in front when it should be behind)
- Stereo/vergence mismatch → eye strain or reduced confidence
- Tracking loss/lighting changes → sudden jumps or inability to anchor
Read more
“True spatial interaction” in AR glasses means the system can understand real 3D space, track the user’s viewpoint precisely, and then render/allow interaction in a way that feels physically correct—especially when the user needs accurate depth (near vs far), scale, and alignment. For depth-critical workflows, this must work reliably in motion.
1) What makes interaction “spatial”?
A. 6-DoF tracking (pose)
The glasses continuously estimate the user’s head pose:
- Position in 3D space (x, y, z)
- Orientation (roll/pitch/yaw)
Depth-critical workflows depend on low drift and low latency so that virtual objects stay “stuck” to the real world.
B. World understanding (mapping)
The system builds a representation of the environment:
- Feature points / SLAM map
- Planes (walls/floors) and sometimes meshes
- Recognized objects or anchors (e.g., “this specific machine part”)
This provides a coordinate frame so a virtual object can be placed at a specific real location.
C. Anchoring & stability
When you “place” something (a label, tool guide, 3D model), it must remain fixed relative to the real scene even when you move. Depth-critical tasks fail when anchors slide or scale incorrectly.
2) What makes it “depth-critical”?
Depth-critical means errors in depth translate directly into wrong actions, for example:
- Aligning fasteners or parts
- Drilling/cutting path guidance
- Training where correct positioning matters
- Medical/procedural-like guidance (even if not a medical device)
So the system must deliver:
- Accurate relative depth (near vs far)
- Correct scale (1:1 size or known calibration)
- Consistent parallax (stereo cues + correct rendering)
3) How stereo/binocular helps depth-critical workflows
Binocular glasses can render stereoscopic depth:
- Each eye sees a slightly different image, matching real-world parallax
- This improves perceived depth and makes “reach/align” tasks more natural
However, stereo only helps if:
- Optical alignment is correct
- Tracking is good
- Rendering matches the user’s actual viewpoint (latency matters)
4) Interaction methods that use 3D space
To interact “in space,” the system needs a way to target 3D points/objects:
A. Gaze + ray casting (common)
- Eye tracking gives a gaze direction
- The system casts a ray into the reconstructed scene
- It determines the 3D point you’re looking at (for selection, grabbing, “tap in space”)
B. Controller/hand tracking
- Hand/controller pose is tracked in 3D
- The user “grabs” virtual objects or aligns tools
- Constraints help prevent unrealistic interactions (e.g., snapping to edges/axes)
C. Spatial gestures
- Pinch to select
- Grab to move
- Rotate to align
- Confirm/cancel actions with air taps or hand poses
Depth-critical benefit: the “target” is a 3D coordinate, not a 2D screen pixel.
5) The rendering pipeline must be correct
For depth-critical workflows, rendering must be physically consistent:
- Compute gaze/head pose at render time
- Project 3D anchors into the display
- Apply occlusion handling (virtual object hidden behind real objects when appropriate)
- Maintain correct depth ordering (so a virtual tool guide doesn’t “float through” the real tool)
This often requires:
- Depth map estimation (from cameras)
- Occlusion meshes or learned depth
- Accurate camera calibration
6) Latency and prediction (why timing is critical)
If pose updates arrive late:
- The virtual object appears to lag behind
- Stereo depth cues can become uncomfortable
- Alignment tasks become error-prone
So systems use:
- Sensor fusion (IMU + vision)
- Motion prediction (estimate where the user will be at display time)
- Late latching/reprojection (update pose as late as possible before scanout)
7) Typical depth-critical workflow examples (how it plays out)
A. Maintenance/assembly “Place the part here”
- The system detects the assembly area/anchors (or recognizes the part)
- Shows a 3D placement ghost/guide at the correct location
- User aligns screws/parts using gaze + hand/controller targeting
- Occlusion + stereo help confirm “in/out” depth
B. “Follow the drill path.”
- A path is computed in 3D, tied to the real surface
- As you move, the path remains locked to the surface
- Depth accuracy ensures the virtual trajectory corresponds to the physical cut/drill location
C. Training simulation for correct positioning
- Virtual anatomy/tools placed in real-ish space
- Scoring based on 3D deviation tolerances
- Binoculars improve realism, but tracking accuracy is the bigger determinant
8) What could still go wrong (key failure modes)
- SLAM drift → anchors slowly shift, causing depth errors
- Scale miscalibration → virtual objects seem too big/small
- Bad occlusion → depth looks wrong (virtual tool appears in front when it should be behind)
- Stereo/vergence mismatch → eye strain or reduced confidence
- Tracking loss/lighting changes → sudden jumps or inability to anchor
Read more
What are the advantages and disadvantages of monocular and binocular AR glasses?
Posted by Technology Co., Ltd Shenzhen Mshilor
Monocular AR glasses (one eye display)
Advantages
- Lower cost & easier manufacturing: Fewer optical channels (one display/beam path) generally reduces BOM cost and complexity.
- Lighter and simpler ergonomics: Often less weight and bulk; may be more comfortable for long wear.
- Smaller power/compute budget (in some designs): With fewer display/processing paths, power consumption can be lower.
- Sufficient for many “assistive” use cases: For UI overlays (navigation text, notifications, simple annotations), true stereo depth isn’t always required.
Disadvantages
- No true stereoscopic depth cues: Depth perception is limited; it relies on monocular depth cues (size, perspective, occlusion) and/or external sensors.
- Harder for precise spatial tasks: Less suitable for fine-grained “place this object here” experiences (AR assembly, surgery planning, accurate alignment).
- Potential discomfort/visual strain: If virtual content doesn’t match real-world depth/vergence expectations well (or if users expect depth that isn’t present), some users may experience fatigue.
- Reduced immersion: Many people perceive binocular/stereo as more natural and “real,” especially for games, training, and advanced 3D visualization.
Binocular AR glasses (two-eye displays)
Advantages
- Better depth perception (stereoscopy): Two displays enable stereoscopic rendering and more convincing spatial cues, improving usability for 3D tasks.
- More natural and immersive experience: Most users perceive binocular AR as more “grounded” in the environment.
- Improved alignment/occlusion realism: With stereo, it’s easier to render convincing near/far relationships and reduce “floating” effects (assuming tracking is good).
- Broader application range: Better suited to spatial training, collaborative AR, object placement, and any workflow needing accurate depth.
Disadvantages
- Higher cost & complexity: More optics, calibration, and display processing; typically higher BOM and R&D cost.
- More weight and power draw: Often heavier; may increase battery/thermal constraints.
- Calibration sensitivity: Misalignment between left/right channels can cause discomfort, eye strain, or reduced image quality.
- More challenging manufacturing/QA: More ways for devices to drift out of calibration over time (temperature, shock, wear).
- Still limited by tracking: If eye/pose tracking is imperfect, stereo can amplify mismatch discomfort (even though stereo is “better,” bad calibration/misalignment is worse).
Quick Decision Guide
- Choose a monocular if your priorities are cost, comfort, and simple overlay experiences such as text/labels, lightweight navigation, and an 'assistant' UI.
- Choose binoculars if you require true spatial interaction and depth-critical workflows such as object placement, 3D visualization, or training/medical-grade precision.
If you tell me your target use case (e.g., field service instructions, navigation, training simulation, gaming, industrial design), I can suggest which option is the better fit and which technical features matter most, such as stereo rendering, eye tracking, depth sensors, and tracking latency.
Read more
Monocular AR glasses (one eye display)
Advantages
- Lower cost & easier manufacturing: Fewer optical channels (one display/beam path) generally reduces BOM cost and complexity.
- Lighter and simpler ergonomics: Often less weight and bulk; may be more comfortable for long wear.
- Smaller power/compute budget (in some designs): With fewer display/processing paths, power consumption can be lower.
- Sufficient for many “assistive” use cases: For UI overlays (navigation text, notifications, simple annotations), true stereo depth isn’t always required.
Disadvantages
- No true stereoscopic depth cues: Depth perception is limited; it relies on monocular depth cues (size, perspective, occlusion) and/or external sensors.
- Harder for precise spatial tasks: Less suitable for fine-grained “place this object here” experiences (AR assembly, surgery planning, accurate alignment).
- Potential discomfort/visual strain: If virtual content doesn’t match real-world depth/vergence expectations well (or if users expect depth that isn’t present), some users may experience fatigue.
- Reduced immersion: Many people perceive binocular/stereo as more natural and “real,” especially for games, training, and advanced 3D visualization.
Binocular AR glasses (two-eye displays)
Advantages
- Better depth perception (stereoscopy): Two displays enable stereoscopic rendering and more convincing spatial cues, improving usability for 3D tasks.
- More natural and immersive experience: Most users perceive binocular AR as more “grounded” in the environment.
- Improved alignment/occlusion realism: With stereo, it’s easier to render convincing near/far relationships and reduce “floating” effects (assuming tracking is good).
- Broader application range: Better suited to spatial training, collaborative AR, object placement, and any workflow needing accurate depth.
Disadvantages
- Higher cost & complexity: More optics, calibration, and display processing; typically higher BOM and R&D cost.
- More weight and power draw: Often heavier; may increase battery/thermal constraints.
- Calibration sensitivity: Misalignment between left/right channels can cause discomfort, eye strain, or reduced image quality.
- More challenging manufacturing/QA: More ways for devices to drift out of calibration over time (temperature, shock, wear).
- Still limited by tracking: If eye/pose tracking is imperfect, stereo can amplify mismatch discomfort (even though stereo is “better,” bad calibration/misalignment is worse).
Quick Decision Guide
- Choose a monocular if your priorities are cost, comfort, and simple overlay experiences such as text/labels, lightweight navigation, and an 'assistant' UI.
- Choose binoculars if you require true spatial interaction and depth-critical workflows such as object placement, 3D visualization, or training/medical-grade precision.
If you tell me your target use case (e.g., field service instructions, navigation, training simulation, gaming, industrial design), I can suggest which option is the better fit and which technical features matter most, such as stereo rendering, eye tracking, depth sensors, and tracking latency.
Read more
How does Integrate Open AI (GPT or other models) into AR glasses?
Posted by Technology Co., Ltd Shenzhen Mshilor
Here below is a practical, end-to-end guide for integrating OpenAI (GPT or other models) into AR glasses. It covers architecture options (cloud, on-device, hybrid), networking and latency, APIs and data flows, UI/UX patterns for AR, security/privacy, hardware/software requirements, and an example implementation plan with priorities and testing.
- Goals & constraints
- Requirements that determine choices: real-time responsiveness (low latency), offline capability, privacy/sensitivity of user data, power and thermal limits, form factor, and available network connectivity.
- Typical AR use cases: voice assistant, contextual scene understanding, OCR + translation, multimodal Q&A, summarization, code generation, multimodal input (camera + voice + gaze).
- Architecture options (trade-offs)
- Cloud-only
- Pros: access to largest models, rapid updates, low device compute.
- Cons: network dependency, higher latency, bandwidth costs, privacy concerns.
- On-device (local models)
- Pros: low latency, offline use, privacy.
- Cons: limited model size/accuracy, heavy hardware (NPU/DSP), storage and power constraints.
- Hybrid (recommended for many AR scenarios)
- Local edge processing for ultra-low-latency tasks (ASR, wake-word, basic NLU, sensor fusion, ephemeral intent detection).
- Cloud for heavy LLM inference, multimodal reasoning, summarization, long context, large-model accuracy.
- Dynamic offloading based on connectivity, latency, power, and privacy policies.
- System components
- AR device (glasses)
- Sensors: front-facing camera(s), IMU (accelerometer/gyro), eye-tracking, microphone(s), optional depth sensor.
- Compute: SoC + NPU/DSP for on-device inference; Wi-Fi/5G modem.
- Runtime: OS (Android/AOSP/Freertos/RTOS), container/sandbox for AI clients.
- UI: visual overlay renderer (waveguide HUD), spatial audio, gesture/touch input.
- Local AI stack
- On-device ASR (wake-word, local voice commands), small intent model (edge GPT-like), sensor preprocessing (frame selection, compression).
- SDKs: ONNX/TFLite/NNAPI/Hexagon/Vulkan/Metal for model acceleration.
- Cloud backend
- OpenAI API (or private LLM hosting): text completion, chat, multimodal APIs, embedding services.
- Session manager: maintains conversation state and context windows, handles authentication, billing, and rate-limiting.
- Edge service / relay: regional edge nodes to reduce latency, manage model selection and dynamic compression.
- Data store: optional encrypted logs, telemetry, user profiles (with consent).
- Network & sync
- Protocols: HTTPS/HTTP2 or WebSockets for streaming responses; QUIC/HTTP3 for lower latency where available.
- Compression: protobuf/gRPC or binary frames + delta compression for video/sensor metadata.
- Fallbacks: store-and-forward when connectivity is poor; progressive results when partial inference available.
- Typical data flow (hybrid example)
- Wake-word detected locally → local ASR transcribes to text → local intent classifier decides (local action vs cloud request).
- If local: run small NLU and perform device control / quick replies.
- If cloud: preprocess inputs (trim/compress video frames, include extracted scene metadata and embeddings) → send request to OpenAI endpoint (chat completion/multimodal) with relevant context and system prompt → stream partial results back via WebSocket/HTTP2 → render text, TTS, or visual overlays in AR.
- For heavy vision tasks: run lightweight on-device vision (object detection/segmentation) and send compressed descriptors or embeddings to cloud for higher-level reasoning (e.g., "What is this machine part and how to repair it?").
- Latency targets & techniques
- Perceptual targets:
- Voice command acknowledgment: <100–200 ms (local)
- Full cloud-based reasoning response: acceptable 300–800 ms for short text; up to seconds for longer multimodal outputs.
- Techniques:
- Streaming responses (chunked tokens) so UI can start rendering early.
- Progressive disclosure: show partial results, then refine.
- Pre-fetching and caching of prompts, common responses, and embeddings.
- Use edge nodes & persistent connections to reduce handshake latency.
- Prioritize on-device inference for immediate feedback (wake-word, UI navigation).
- API & prompt engineering
- Use system prompts and role design to constrain behavior (safety, brevity, persona).
- Keep context compact: convert sensor data to structured metadata and embeddings to avoid sending raw video.
- Example request pattern:
- system: device constraints and persona
- user: short transcribed query + device state (location, focused object embedding)
- tools: reference to external APIs (object identification, product DB)
- Use OpenAI streaming endpoints for progressive UX and implement token-level rendering.
- Privacy, security & compliance
- Minimize PII and sensitive imagery being sent off-device. Use local anonymization (blur faces, remove GPS) where appropriate.
- Use end-to-end TLS, certificate pinning for backend connections.
- Tokenize and store minimal session data; encrypt at rest with device keys and rotate keys.
- Consent & transparency: explicit user consent to upload camera/audio to cloud; visible indicators when sensor data transmitted.
- On-device privacy modes and enterprise policies to force local-only operation.
- Comply with GDPR, CCPA, sector-specific regulations for audio/visual data.
- UX & interaction patterns for AR
- Input modalities: voice primary, complemented by gestures, gaze + controller, and touch.
- Output modalities: spatial overlays pinned to world objects, heads-up text, spatial audio, haptic feedback.
- Design for short, skimmable outputs; avoid long scrolling text in HUD—use summaries and layered detail (tap to expand).
- Context-aware content: anchor responses to world objects (e.g., show instructions next to the machine part).
- Error handling: gracefully handle offline mode; show confidence indicators and "[processing]" states.
- Hardware & software requirements
- Minimum device features for hybrid approach:
- Dual/multi-core SoC + 1 TOPS-class NPU for on-device models.
- Mic array and beamforming for robust ASR.
- Wi-Fi 6/5G modem for low-latency connectivity.
- 4–8 GB RAM (more for advanced edge processing), NVMe or fast flash storage.
- Power budget & thermal: ensure bursts for inference only when needed.
- Software stack:
- Containerized inference runtimes, model quantization toolchain (int8/4-bit), accelerators via vendor SDKs.
- TTS runtime (server or small on-device TTS), ASR engine (VAD + local models), media codec support.
- SDKs for OpenAI API (or custom LLM host), WebRTC/WebSocket, secure auth (OAuth2 / device auth).
- Example implementation plan (MVP → Production)
- Phase 0: Requirements & risk
- Define use cases (e.g., voice assistant, repair guide), target latency, privacy settings, and user journeys.
- Phase 1 (MVP)
- Implement local wake-word + local ASR or cloud ASR fallback.
- Connect to OpenAI API for simple chat completion; implement streaming responses and basic overlay rendering.
- Basic prompt templates and context packaging (metadata only).
- Simple auth & TLS, consent flow for camera use.
- Phase 2 (Hybrid features)
- Add on-device tiny vision models for object detection; send embeddings to the cloud for reasoning.
- Implement edge relay and response caching; tune streaming UX.
- Add TTS with spatial audio and multi-language support.
- Phase 3 (Optimization & production)
- Quantize/compile models for device NPU to move more tasks local.
- Add enterprise privacy modes, logging controls, and compliance audits.
- Scale backend: regional edge nodes, autoscaling, monitoring and cost optimization.
- Phase 4 (Advanced)
- On-device multimodal LLMs for offline reasoning; federation/sync model weights for personalization.
- Sophisticated context stitching across sessions and devices.
- Example technical snippets & flows
- Use streaming API (pseudo-flow):
- Open WebSocket to backend with device token.
- Send initial metadata JSON (device_state, scene_embeddings, recent_tokens).
- Start sending transcript; receive token stream; render tokens immediately.
- Edge optimization: compute embeddings locally (CLIP-like) and send embeddings instead of images.
- Risks & mitigation
- Privacy breaches: mitigate via local filters and strict consent.
- Latency spikes: use fallback local behaviors and graceful degradation.
- Cost: offload inference selectively; use caching and shorter prompts.
- Safety: guardrails in prompts, content filters, and supervised escape handling.
- Metrics to monitor
- Round-trip latency (ASR->LLM->render)
- Token throughput & streaming jitter
- Cloud vs local hit ratio (how often offload required)
- Power consumption per session
- User satisfaction and task success rate
- Recommended tools & SDKs
- OpenAI API (chat/completions/embeddings; streaming)
- On-device ML runtimes: ONNX Runtime, TensorFlow Lite, Core ML, NNAPI, vendor NPU SDKs
- ASR/TTS: Mozilla DeepSpeech, Vosk, Whisper (server or optimized local), Pico TTS or commercial SDKs
- Networking: WebRTC, gRPC/HTTP2, QUIC
- Security: mTLS, OAuth2 device flow, secure enclave for key storageHer
Read more
Here below is a practical, end-to-end guide for integrating OpenAI (GPT or other models) into AR glasses. It covers architecture options (cloud, on-device, hybrid), networking and latency, APIs and data flows, UI/UX patterns for AR, security/privacy, hardware/software requirements, and an example implementation plan with priorities and testing.
- Goals & constraints
- Requirements that determine choices: real-time responsiveness (low latency), offline capability, privacy/sensitivity of user data, power and thermal limits, form factor, and available network connectivity.
- Typical AR use cases: voice assistant, contextual scene understanding, OCR + translation, multimodal Q&A, summarization, code generation, multimodal input (camera + voice + gaze).
- Architecture options (trade-offs)
- Cloud-only
- Pros: access to largest models, rapid updates, low device compute.
- Cons: network dependency, higher latency, bandwidth costs, privacy concerns.
- On-device (local models)
- Pros: low latency, offline use, privacy.
- Cons: limited model size/accuracy, heavy hardware (NPU/DSP), storage and power constraints.
- Hybrid (recommended for many AR scenarios)
- Local edge processing for ultra-low-latency tasks (ASR, wake-word, basic NLU, sensor fusion, ephemeral intent detection).
- Cloud for heavy LLM inference, multimodal reasoning, summarization, long context, large-model accuracy.
- Dynamic offloading based on connectivity, latency, power, and privacy policies.
- System components
- AR device (glasses)
- Sensors: front-facing camera(s), IMU (accelerometer/gyro), eye-tracking, microphone(s), optional depth sensor.
- Compute: SoC + NPU/DSP for on-device inference; Wi-Fi/5G modem.
- Runtime: OS (Android/AOSP/Freertos/RTOS), container/sandbox for AI clients.
- UI: visual overlay renderer (waveguide HUD), spatial audio, gesture/touch input.
- Local AI stack
- On-device ASR (wake-word, local voice commands), small intent model (edge GPT-like), sensor preprocessing (frame selection, compression).
- SDKs: ONNX/TFLite/NNAPI/Hexagon/Vulkan/Metal for model acceleration.
- Cloud backend
- OpenAI API (or private LLM hosting): text completion, chat, multimodal APIs, embedding services.
- Session manager: maintains conversation state and context windows, handles authentication, billing, and rate-limiting.
- Edge service / relay: regional edge nodes to reduce latency, manage model selection and dynamic compression.
- Data store: optional encrypted logs, telemetry, user profiles (with consent).
- Network & sync
- Protocols: HTTPS/HTTP2 or WebSockets for streaming responses; QUIC/HTTP3 for lower latency where available.
- Compression: protobuf/gRPC or binary frames + delta compression for video/sensor metadata.
- Fallbacks: store-and-forward when connectivity is poor; progressive results when partial inference available.
- Typical data flow (hybrid example)
- Wake-word detected locally → local ASR transcribes to text → local intent classifier decides (local action vs cloud request).
- If local: run small NLU and perform device control / quick replies.
- If cloud: preprocess inputs (trim/compress video frames, include extracted scene metadata and embeddings) → send request to OpenAI endpoint (chat completion/multimodal) with relevant context and system prompt → stream partial results back via WebSocket/HTTP2 → render text, TTS, or visual overlays in AR.
- For heavy vision tasks: run lightweight on-device vision (object detection/segmentation) and send compressed descriptors or embeddings to cloud for higher-level reasoning (e.g., "What is this machine part and how to repair it?").
- Latency targets & techniques
- Perceptual targets:
- Voice command acknowledgment: <100–200 ms (local)
- Full cloud-based reasoning response: acceptable 300–800 ms for short text; up to seconds for longer multimodal outputs.
- Techniques:
- Streaming responses (chunked tokens) so UI can start rendering early.
- Progressive disclosure: show partial results, then refine.
- Pre-fetching and caching of prompts, common responses, and embeddings.
- Use edge nodes & persistent connections to reduce handshake latency.
- Prioritize on-device inference for immediate feedback (wake-word, UI navigation).
- API & prompt engineering
- Use system prompts and role design to constrain behavior (safety, brevity, persona).
- Keep context compact: convert sensor data to structured metadata and embeddings to avoid sending raw video.
- Example request pattern:
- system: device constraints and persona
- user: short transcribed query + device state (location, focused object embedding)
- tools: reference to external APIs (object identification, product DB)
- Use OpenAI streaming endpoints for progressive UX and implement token-level rendering.
- Privacy, security & compliance
- Minimize PII and sensitive imagery being sent off-device. Use local anonymization (blur faces, remove GPS) where appropriate.
- Use end-to-end TLS, certificate pinning for backend connections.
- Tokenize and store minimal session data; encrypt at rest with device keys and rotate keys.
- Consent & transparency: explicit user consent to upload camera/audio to cloud; visible indicators when sensor data transmitted.
- On-device privacy modes and enterprise policies to force local-only operation.
- Comply with GDPR, CCPA, sector-specific regulations for audio/visual data.
- UX & interaction patterns for AR
- Input modalities: voice primary, complemented by gestures, gaze + controller, and touch.
- Output modalities: spatial overlays pinned to world objects, heads-up text, spatial audio, haptic feedback.
- Design for short, skimmable outputs; avoid long scrolling text in HUD—use summaries and layered detail (tap to expand).
- Context-aware content: anchor responses to world objects (e.g., show instructions next to the machine part).
- Error handling: gracefully handle offline mode; show confidence indicators and "[processing]" states.
- Hardware & software requirements
- Minimum device features for hybrid approach:
- Dual/multi-core SoC + 1 TOPS-class NPU for on-device models.
- Mic array and beamforming for robust ASR.
- Wi-Fi 6/5G modem for low-latency connectivity.
- 4–8 GB RAM (more for advanced edge processing), NVMe or fast flash storage.
- Power budget & thermal: ensure bursts for inference only when needed.
- Software stack:
- Containerized inference runtimes, model quantization toolchain (int8/4-bit), accelerators via vendor SDKs.
- TTS runtime (server or small on-device TTS), ASR engine (VAD + local models), media codec support.
- SDKs for OpenAI API (or custom LLM host), WebRTC/WebSocket, secure auth (OAuth2 / device auth).
- Example implementation plan (MVP → Production)
- Phase 0: Requirements & risk
- Define use cases (e.g., voice assistant, repair guide), target latency, privacy settings, and user journeys.
- Phase 1 (MVP)
- Implement local wake-word + local ASR or cloud ASR fallback.
- Connect to OpenAI API for simple chat completion; implement streaming responses and basic overlay rendering.
- Basic prompt templates and context packaging (metadata only).
- Simple auth & TLS, consent flow for camera use.
- Phase 2 (Hybrid features)
- Add on-device tiny vision models for object detection; send embeddings to the cloud for reasoning.
- Implement edge relay and response caching; tune streaming UX.
- Add TTS with spatial audio and multi-language support.
- Phase 3 (Optimization & production)
- Quantize/compile models for device NPU to move more tasks local.
- Add enterprise privacy modes, logging controls, and compliance audits.
- Scale backend: regional edge nodes, autoscaling, monitoring and cost optimization.
- Phase 4 (Advanced)
- On-device multimodal LLMs for offline reasoning; federation/sync model weights for personalization.
- Sophisticated context stitching across sessions and devices.
- Example technical snippets & flows
- Use streaming API (pseudo-flow):
- Open WebSocket to backend with device token.
- Send initial metadata JSON (device_state, scene_embeddings, recent_tokens).
- Start sending transcript; receive token stream; render tokens immediately.
- Edge optimization: compute embeddings locally (CLIP-like) and send embeddings instead of images.
- Risks & mitigation
- Privacy breaches: mitigate via local filters and strict consent.
- Latency spikes: use fallback local behaviors and graceful degradation.
- Cost: offload inference selectively; use caching and shorter prompts.
- Safety: guardrails in prompts, content filters, and supervised escape handling.
- Metrics to monitor
- Round-trip latency (ASR->LLM->render)
- Token throughput & streaming jitter
- Cloud vs local hit ratio (how often offload required)
- Power consumption per session
- User satisfaction and task success rate
- Recommended tools & SDKs
- OpenAI API (chat/completions/embeddings; streaming)
- On-device ML runtimes: ONNX Runtime, TensorFlow Lite, Core ML, NNAPI, vendor NPU SDKs
- ASR/TTS: Mozilla DeepSpeech, Vosk, Whisper (server or optimized local), Pico TTS or commercial SDKs
- Networking: WebRTC, gRPC/HTTP2, QUIC
- Security: mTLS, OAuth2 device flow, secure enclave for key storageHer
Read more
Hot Chips 2026 Driving AR/VR Adoption: A Full-Stack Dissection of Smart Glasses from Sensing to Computing
Posted by Technology Co., Ltd Shenzhen Mshilor
The theme "Driving AR/VR Adoption: A Full-Stack Dissection of Smart Glasses from Sensing to Computing" at Hot Chips 2026 suggests a comprehensive exploration of the various components and technologies that enable augmented reality (AR) and virtual reality (VR) within smart glasses. Here’s a breakdown of what this entails:

1. Sensing Technologies
- Sensors Overview: Discussion on various sensors used in smart glasses, such as cameras, LIDAR, IMUs (Inertial Measurement Units), and environmental sensors.
- Data Capture: How these sensors collect data about the environment and user interactions, critical for immersive experiences.
- Fusion Techniques: Techniques for fusing data from multiple sensors to create a coherent understanding of the surroundings.
2. Processing and Computing
- Chip Architecture: Overview of the semiconductor architectures designed specifically for AR/VR applications, focusing on performance and power efficiency.
- Edge vs. Cloud Computing: Comparison of processing data on-device versus offloading tasks to cloud services, including trade-offs in latency and bandwidth.
- Machine Learning Integration: Implementation of AI/ML algorithms on smart glasses for real-time processing, such as object recognition and environment mapping.
3. Display Technologies
- Display Types: Examination of various display technologies used in smart glasses, including micro OLED, LCD, and waveguide displays.
- Rendering Techniques: Discussing rendering methods that maximize visual fidelity while minimizing latency and power consumption.
- User Interface Design: Best practices for creating intuitive user interfaces within AR/VR environments.
4. Connectivity
- Wireless Standards: Analysis of wireless communication standards (e.g., Wi-Fi 6, Bluetooth 5.0) supporting AR/VR applications, focusing on data throughput and latency.
- Integration with IoT: How smart glasses connect and communicate with other IoT devices to enhance functionalities.
5. User Experience (UX) and Interaction
- Interaction Models: Different models for user interaction, including gesture recognition, voice commands, and touch interfaces.
- Ergonomics and Design: Examining how the design of smart glasses influences user comfort, usability, and adoption rates.
6. Power Management
- Battery Technologies: Innovations in battery design to support the power-hungry features of smart glasses while ensuring a practical form factor.
- Energy Efficiency: Strategies to optimize power usage across the stack—from sensing to computing to display.
7. Market Trends and Adoption Challenges
- Industry Outlook: Analysis of current trends in the AR/VR market, focusing on key players, emerging technologies, and consumer adoption.
- Barriers to Entry: Addressing challenges that may hinder widespread adoption, such as cost, complexity, and the need for content.
Conclusion
This full-stack approach to understanding smart glasses underscores the interdisciplinary nature of AR/VR technology development. By dissecting each component—from sensing through to computing—stakeholders can gain insights into how to drive adoption and create more compelling user experiences in the AR and VR sectors. Hot Chips 2026 will likely foster discussions and innovations that pave the way for the future of smart glasses.
Read more
The theme "Driving AR/VR Adoption: A Full-Stack Dissection of Smart Glasses from Sensing to Computing" at Hot Chips 2026 suggests a comprehensive exploration of the various components and technologies that enable augmented reality (AR) and virtual reality (VR) within smart glasses. Here’s a breakdown of what this entails:
1. Sensing Technologies
- Sensors Overview: Discussion on various sensors used in smart glasses, such as cameras, LIDAR, IMUs (Inertial Measurement Units), and environmental sensors.
- Data Capture: How these sensors collect data about the environment and user interactions, critical for immersive experiences.
- Fusion Techniques: Techniques for fusing data from multiple sensors to create a coherent understanding of the surroundings.
2. Processing and Computing
- Chip Architecture: Overview of the semiconductor architectures designed specifically for AR/VR applications, focusing on performance and power efficiency.
- Edge vs. Cloud Computing: Comparison of processing data on-device versus offloading tasks to cloud services, including trade-offs in latency and bandwidth.
- Machine Learning Integration: Implementation of AI/ML algorithms on smart glasses for real-time processing, such as object recognition and environment mapping.
3. Display Technologies
- Display Types: Examination of various display technologies used in smart glasses, including micro OLED, LCD, and waveguide displays.
- Rendering Techniques: Discussing rendering methods that maximize visual fidelity while minimizing latency and power consumption.
- User Interface Design: Best practices for creating intuitive user interfaces within AR/VR environments.
4. Connectivity
- Wireless Standards: Analysis of wireless communication standards (e.g., Wi-Fi 6, Bluetooth 5.0) supporting AR/VR applications, focusing on data throughput and latency.
- Integration with IoT: How smart glasses connect and communicate with other IoT devices to enhance functionalities.
5. User Experience (UX) and Interaction
- Interaction Models: Different models for user interaction, including gesture recognition, voice commands, and touch interfaces.
- Ergonomics and Design: Examining how the design of smart glasses influences user comfort, usability, and adoption rates.
6. Power Management
- Battery Technologies: Innovations in battery design to support the power-hungry features of smart glasses while ensuring a practical form factor.
- Energy Efficiency: Strategies to optimize power usage across the stack—from sensing to computing to display.
7. Market Trends and Adoption Challenges
- Industry Outlook: Analysis of current trends in the AR/VR market, focusing on key players, emerging technologies, and consumer adoption.
- Barriers to Entry: Addressing challenges that may hinder widespread adoption, such as cost, complexity, and the need for content.
Conclusion
This full-stack approach to understanding smart glasses underscores the interdisciplinary nature of AR/VR technology development. By dissecting each component—from sensing through to computing—stakeholders can gain insights into how to drive adoption and create more compelling user experiences in the AR and VR sectors. Hot Chips 2026 will likely foster discussions and innovations that pave the way for the future of smart glasses.
Read more
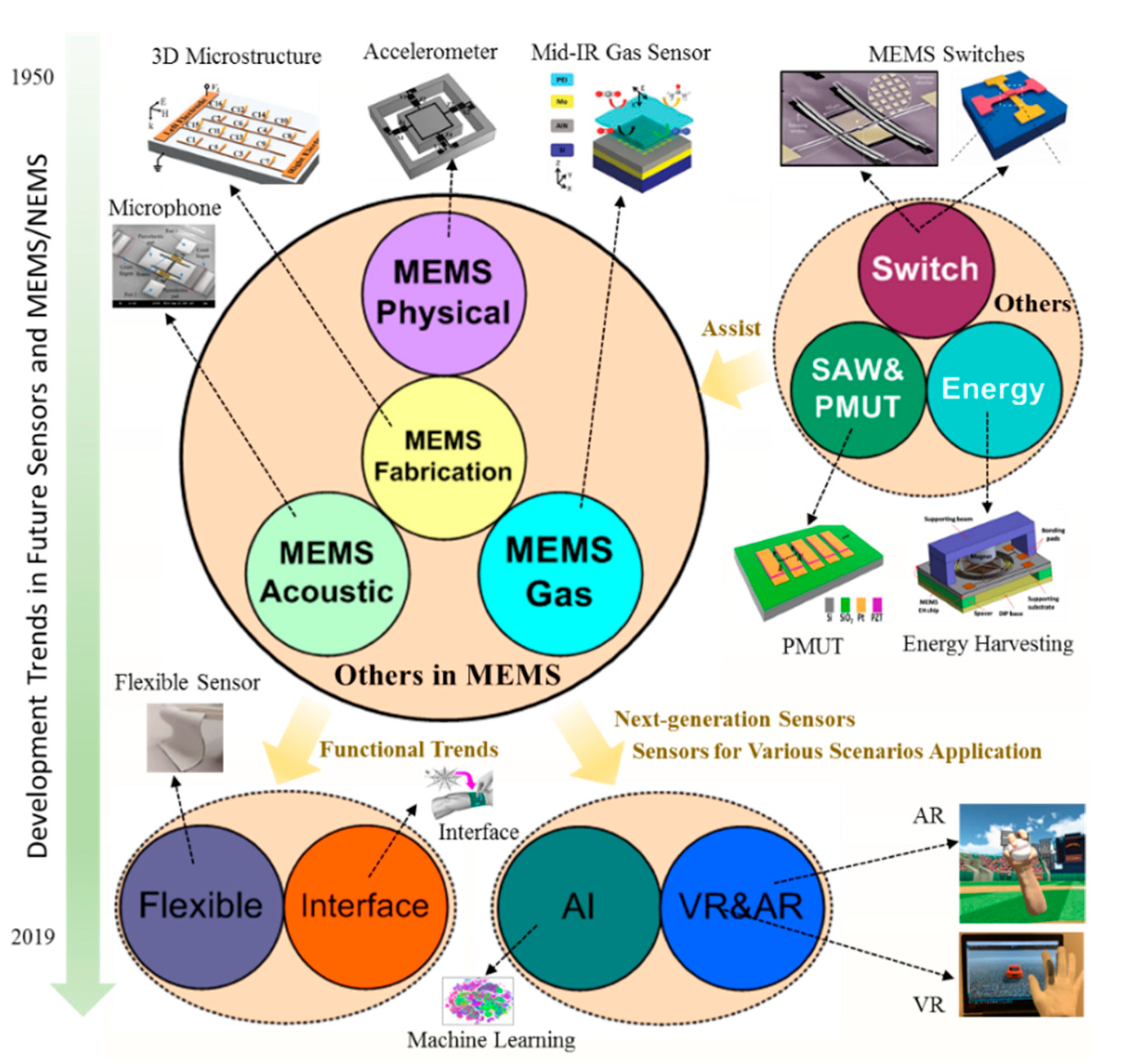
What the Wireless frequency synchronization transmission in AR glasses?
Posted by Technology Co., Ltd Shenzhen Mshilor
Wireless frequency synchronization transmission in AR (Augmented Reality) glasses plays a critical role in ensuring that data and content are transmitted effectively and in real-time. Here’s an overview of the concept and its significance:
1. Definition
Wireless frequency synchronization transmission refers to the coordination of data transmission across multiple wireless channels or devices at specific frequencies to ensure seamless communication and interoperability.
2. Key Components
- Frequency Bands: Utilizes specific frequency ranges (such as 2.4 GHz, 5 GHz, or other bands) for transmitting data.
- Synchronization Protocols: Employs protocols that help multiple devices operate on the same frequency without interference, ensuring accurate timing and data integrity.
3. Importance in AR Glasses
- Real-time Data Processing: AR glasses rely on real-time data (e.g., location, images from cameras, and sensor inputs) to overlay virtual information accurately. Synchronization helps ensure that all data is processed simultaneously.
- Reduced Latency: Synchronization reduces the time delay between data transmission and processing, critical for delivering a smooth, immersive AR experience in applications such as gaming, navigation, or industrial uses.
- Multi-user Interaction: Enables multiple AR devices to interact with each other in shared virtual spaces, enhancing collaborative experiences, such as multiplayer games or educational applications.
4. Applications
- Gaming: In multiplayer AR gaming, synchronized transmission ensures that all players see the same game state, leading to a cohesive gameplay experience.
- Navigation and Mapping: Real-time location data is synchronized to display directions accurately in conjunction with the physical environment.
- Remote Collaboration: In professional settings, AR glasses can be used for remote training or joint projects, necessitating synchronized data for effective collaboration.
5. Challenges
- Interference: Operating on the same frequency can lead to interference from other devices, requiring robust signal processing techniques to manage.
- Bandwidth Limitations: High demands on bandwidth may arise when transmitting complex AR content, necessitating efficient bandwidth management strategies.
- Security: Ensuring data transmitted over synchronized wireless channels is secure from interception or unauthorized access.
6. Future Directions
- 5G Integration: The advent of 5G technology offers higher bandwidth and lower latency, which could greatly enhance synchronization capabilities for AR glasses.
- Advanced Algorithms: Development of smarter synchronization algorithms can improve the efficiency and reliability of wireless frequency transmission.
- Seamless Device Interaction: Future AR systems might better integrate with a broader ecosystem of Internet of Things (IoT) devices, necessitating advanced synchronization across various platforms.
Conclusion
Wireless frequency synchronization transmission is essential for the functioning of AR glasses, facilitating real-time data processing and multi-user interactions. As technology advances, improved methods for synchronization will continue to enhance the capabilities and performance of AR applications.
Read more
Wireless frequency synchronization transmission in AR (Augmented Reality) glasses plays a critical role in ensuring that data and content are transmitted effectively and in real-time. Here’s an overview of the concept and its significance:
1. Definition
Wireless frequency synchronization transmission refers to the coordination of data transmission across multiple wireless channels or devices at specific frequencies to ensure seamless communication and interoperability.
2. Key Components
- Frequency Bands: Utilizes specific frequency ranges (such as 2.4 GHz, 5 GHz, or other bands) for transmitting data.
- Synchronization Protocols: Employs protocols that help multiple devices operate on the same frequency without interference, ensuring accurate timing and data integrity.
3. Importance in AR Glasses
- Real-time Data Processing: AR glasses rely on real-time data (e.g., location, images from cameras, and sensor inputs) to overlay virtual information accurately. Synchronization helps ensure that all data is processed simultaneously.
- Reduced Latency: Synchronization reduces the time delay between data transmission and processing, critical for delivering a smooth, immersive AR experience in applications such as gaming, navigation, or industrial uses.
- Multi-user Interaction: Enables multiple AR devices to interact with each other in shared virtual spaces, enhancing collaborative experiences, such as multiplayer games or educational applications.
4. Applications
- Gaming: In multiplayer AR gaming, synchronized transmission ensures that all players see the same game state, leading to a cohesive gameplay experience.
- Navigation and Mapping: Real-time location data is synchronized to display directions accurately in conjunction with the physical environment.
- Remote Collaboration: In professional settings, AR glasses can be used for remote training or joint projects, necessitating synchronized data for effective collaboration.
5. Challenges
- Interference: Operating on the same frequency can lead to interference from other devices, requiring robust signal processing techniques to manage.
- Bandwidth Limitations: High demands on bandwidth may arise when transmitting complex AR content, necessitating efficient bandwidth management strategies.
- Security: Ensuring data transmitted over synchronized wireless channels is secure from interception or unauthorized access.
6. Future Directions
- 5G Integration: The advent of 5G technology offers higher bandwidth and lower latency, which could greatly enhance synchronization capabilities for AR glasses.
- Advanced Algorithms: Development of smarter synchronization algorithms can improve the efficiency and reliability of wireless frequency transmission.
- Seamless Device Interaction: Future AR systems might better integrate with a broader ecosystem of Internet of Things (IoT) devices, necessitating advanced synchronization across various platforms.
Conclusion
Wireless frequency synchronization transmission is essential for the functioning of AR glasses, facilitating real-time data processing and multi-user interactions. As technology advances, improved methods for synchronization will continue to enhance the capabilities and performance of AR applications.